出た、実用性が無いやつ
それなりに検証してから出したかったけど、モチベがなさすぎるので先に出しておきます
同じ問題を解決している論文が見つかりました。( TwitterID:@tsuka308 さんありがとうございます)
※↓実際に問題を解決するのはこちら(上の論文の [26], 1986 年 )

上の 2 つの文書では “static tree set union” あるいは “marked ancestor problem”(の一種) と呼ばれています。
はじめに
以下、まともに検証していません。
問題
まず $n$ 頂点の木が与えられる。頂点には可換半群の元が設定されている。はじめ、すべての辺は”白”である。次のクエリを処理せよ。
- $\text{dec} (v,w)$ : 辺 $(v,w)$ は “白” でなくなり、 “黒” になる。
- $\text{prod}(v)$ : “白” の辺をすべて取り除いた部分グラフを考える。頂点 $v$ を含む連結成分で総積を求める。
初期化 $O(n)$ 時間、クエリ償却 $O(1)$ 時間。
原理
ビットベクトルに対して decremental neighbor query という問題が定義されています(?)。そして、そのクエリは償却定数時間で処理できます。
この高速化の手法は MoFR (Method of Four Russians) と呼ばれることがあります。
解説
ちょっと問題を簡単にする
問題
まず $n$ 頂点の根付き木が与えられる。はじめ、すべての辺は”白”である。次のクエリを処理せよ。
- $\text{dec} (v,w)$ : 辺 $(v,w)$ は “白” でなくなり、 “黒” になる。
- $\text{top}(v)$ : “白” の辺をすべて取り除いた部分グラフを考える。頂点 $u$ を含む連結成分のうち最も根に近い頂点を求める。
union-find 用の典型的な方法で元の問題に変形できます。
dec_new(v, w) :
lv = top(v)
lw = top(w)
dec(v, w)
if lu != lv : a[top(v)] = a[lv] * a[lw]
prod(v) :
return a[top(v)]木の分割
典型的な方法です。
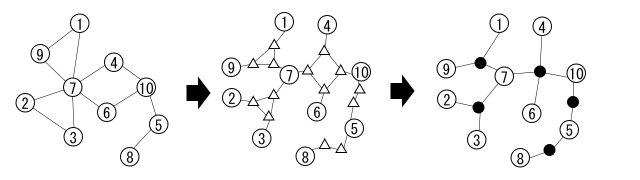
- (1) $n$ 頂点の根付き木を二分木に変形します。元の頂点は disjoint な部分木に対応します。変形後の頂点数は $2n$ 以下です。
-
(2) $f(n)$ を $n$ 以下の整数とします。 $n$ 頂点の二分木を $k$ 個の部分木に分割します。これらの部分木の集合は次の条件を満たします。
- 木の各頂点は、ちょうど $1$ つの部分木に含まれる。
- $1$ つを除いて、部分木の頂点数は $f(n)/2$ 以上 $f(n)$ 以下である。
(1)
子の個数が $2$ 以上の頂点を、それぞれ子の個数より $1$ だけ小さい個数のノードに分割し、二分木をなすようにします。半群の元はその二分木の根に載せます。
(2)
根を始点とする BFS の逆順に処理します。部分木の大きさが $f(n)/2$ 以上になったらその部分木を採用し、木から取り除きます。二分木なので、採用される部分木の頂点数は $1+2(f(n)/2-1)=f(n)-1$ 以下です。最後に根を含む部分木を採用するときだけ、頂点数は $f(n)/2$ 未満になる可能性があります。条件から、 $k\leq 2n/f(n)+1$ が示されます。
この手順は $O(n)$ 時間で実行できます。
すべての組み合わせの列挙
与えられる根付き木も不定として、問題を処理している過程で現れうる木の構造は何通りあるでしょうか?根付き木のオイラーツアーを適当にとると、根付き木は $O(2^{2n})$ 通りとわかります。辺が “白” か “黒” かも考慮して、 $O(2^{3n})$ 通りになります。
例えば、次の情報を事前に計算したとすれば、すべてのクエリに定数時間で答えられるはずです。
- 与えられた根付き木をオイラーツアーに変形したときの対応関係
- 状態 $s$ と辺 $e$ の組について、クエリ $\text{dec}$ で辺 $e$ が選ばれたときの次の状態 $A(s,e)$
- 状態 $s$ と頂点 $v$ の組について、クエリ $\text{top}(v)$ の答え
前計算の計算量は $O^{\ast}(2^{3n})$ になりますが、たくさんのインスタンスがあっても同じ計算量になります。
$n=\frac{1}{4}\log_2(N)$ とすることで、計算量は $o(N)$ となります。
union-find の要素数が少ない場合
要素数 $O(n/\log n)$ の union-find を考えます。例えば union by size と path compression(2023/08/17 追記) を採用していれば、計算量を初期化 $O(n)$ 、クエリ償却 $O(1)$ と考えてよいことが知られています。
本体
$n$ 頂点の木を二分木に変形します。二分木の頂点数を $n_2$ として、 $f(n_2)=\frac{1}{4}\log_2(n_2/2)$ として分割します。ここで現れる部分木についてすべての状態を前計算しますが、頂点数は $\frac{1}{4}\log_2(n)$ 以下なので、計算量は $o(n)$ です。
部分木の根 $r$ に対応して union-find のノードを作ります。 union-find のノードの個数は $O(n/\log n)$ です。 union-find の代表元では $\text{top}(r)$ を管理します。すると全体の $\text{top}$ が求まります。
top(v) :
w = small_top(v)
if w == small(w).root : return unionfind.top(w)
return wつまり、次の手順で $\text{top}$ にアクセスします。
- 小さい部分木の範囲を、テーブルのアクセスで処理する。
- 小さい部分木の根まで行ったら、 union-find で最後まで処理する。
各頂点で、次で定義される値 $\text{leader}[v]$ を管理します。
- $v=\text{top}(v)$ かつ、ある部分木の根 $r$ があって $v=\text{top}(r)$ となる場合、そのような $r$ のうちの $1$ つ。
- そうでない場合、 $\text{nil}$ 。
クエリ $\text{dec}$ に対しては、次のような実装で処理できます。
dec(v, w) :
if parent(v) == w : v, w = w, v
v = top(v)
w = top(w)
a[v] = a[v] * a[w]
if v == w : return
if small(v).root == small(w).root : small(v).dec(v, w)
d = unionfind.unite(leader[v], leader[w])
unionfind.data_top[d] = v
leader[v] = d
leader[w] = nil以上で、データ構造全体で初期化 $O(n)$ 、クエリ償却 $O(1)$ 時間で $\text{top}$ と $\text{dec}$ を実装できました。よって、 $\text{prod}$ も実装できます。